Prerequisites
This guide and demo requires a GraphQL API that supports persisted queries. To get started quickly from your existing APIs, check out our quickstart guide on Apollo Connectors.
Apollo Connectors Quickstart
Organizations are building new experiences with LLMs like ChatGPT, Gemini, and Claude. Some simple apps can get away with basic access to data, such as looking up who played that one character in the show we watched last night. But how often do we need just a single piece of static information? As soon as our customers need to do something like place an order or check the current delivery status, we quickly move beyond simply reading a value from a table.
Any meaningful experience will ultimately need to take action on a user's behalf; for that, we need APIs. By using GraphQL as an API access layer, we can provide governable, trusted access to our existing APIs, whether they’re powering a mobile app or an LLM-driven chatbot.
This guide and demo requires a GraphQL API that supports persisted queries. To get started quickly from your existing APIs, check out our quickstart guide on Apollo Connectors.
What do the apps we use every day have in common with our favorite musicians? We come back to them so often because they feel personal. We connect more deeply to musicians when we feel like their songs are written directly to us and about things we’ve personally experienced. By the same token, we’re more likely to return to experiences and apps that feel like they were built just for us. We’ll use a streaming service more often if it knows we like Westerns and gives us good recommendations, but we might trust it less if the service pushes recommendations for reality TV.
Personalization works. According to a recent McKinsey survey, companies with faster growth rates derive 40 percent more of their revenue from personalization than their slower-growing counterparts.
Now that the initial flurry of new AI projects has settled, organizations find that their AI-driven experiences are only as valuable as the timely and personalized data they can provide to their customers. Applications that are simply a thin wrapper around a third-party LLM aren’t a differentiable customer experience and can present security and legal risks to an organization. On the other hand, companies that build deep integrations create the best experience for their customers and have an outsized impact on their business.
Differentiation requires data, and APIs are the best way to deliver that information to AI workloads. But how can LLMs and AI-driven experiences best access the APIs that already power a business?
Large language models (LLMs) today are good at many things, but orchestrating complex sequences of tasks isn’t one of them. The AI systems we have today lack the reasoning skills and, in some cases, the training data, to make sense of these sequences without hallucination. If we break down the workflow required to answer a seemingly simple question, we can quickly see why this is so difficult.
For example, to do something like check the status of an order and when it's scheduled for delivery, the LLM must:
Reliably understand a customer order and identify gaps in its understanding
Know which services are available to query
Know which services map to each specific part of the order
Know the sequence that the services must be called
Know which warehouse each item in the order is being shipped from
Know the shipping method and understand how to query the shipper such as FedEx, UPS, or USPS
Understand dependencies between the services and which can be issued in parallel or sequence
Issue requests to many different services to fill those gaps to satisfy the user's request
Handle any errors or issues in any given service response and potentially retry a request
Translate the responses back to the user
That’s asking a lot of any system, and it's certainly not a single value in a database that we could just vectorize and access indiscriminately. To further complicate things, remember that this isn’t a program against which we write perfectly reliable unit tests or where we can be assured of the order of operations. It’s a stochastic runtime environment that can respond unpredictably.
Directly connecting an unpredictable system to all the APIs that run our business is like hardwiring a phone charger to a power main. We could do it, but there are safer, more governable ways of getting data into an AI-driven experience. Engineering leaders must make a balanced trade-off when designing systems integrating an organization's data into an LLM experience: how do you enable developers to innovate rapidly while maintaining a solid security and governance posture that reduces risk?
These requirements and trade-offs carry over to the API layer as well. Customer experiences rely on dozens and even hundreds of API endpoints to deliver accurate and contextual responses to users. The large language models (LLMs) that power AI-driven applications have no inherent knowledge of our data or how our data entities relate. They rely on the backend to provide this for them. If we rely solely on REST APIs, this leaves us with two options:
Rely on LLMs to fetch data from discrete domain APIs. While we can use an LLM to make one or two network requests, sequenced using Function Calling, for example, they’re not yet well-suited for orchestrating dozens of requests.
Build and support new backends-for-frontends to support these experiences. As we introduce new data and endpoints, each individual team must test for breaking changes, over- and under-fetching, and security concerns. Building BFF after BFF introduces technical debt and can slow developer velocity and innovation because of the increased surface area of the services to protect, monitor, and maintain.
Looking beyond simple API requests and function calls, we find a third approach that allows us to reuse our existing APIs while still protecting our data: Federated GraphQL.
GraphQL abstracts the complexity of sequencing calls to multiple REST APIs for any number of clients, and GraphQL federation enables your team to scale GraphQL across API teams. Individual teams can hone and craft a subset of the chatbot user experience without requiring a sprawl of BFFs to maintain. To mitigate risk, Apollo GraphOS provides the security and governance features that ensure each module of our chatbot can access the information it needs to do its job and nothing more. So, instead of trading developer velocity for stability and security, we get the best of both worlds.
GraphQL federation is an ideal API access layer for distributed architectures. Rather than delivering services to frontend teams as a series of handwritten BFFs, service teams can deliver APIs as a composable and semantic graph – a supergraph. Developers creating AI-driven experiences can fetch all the data they need from a single endpoint.
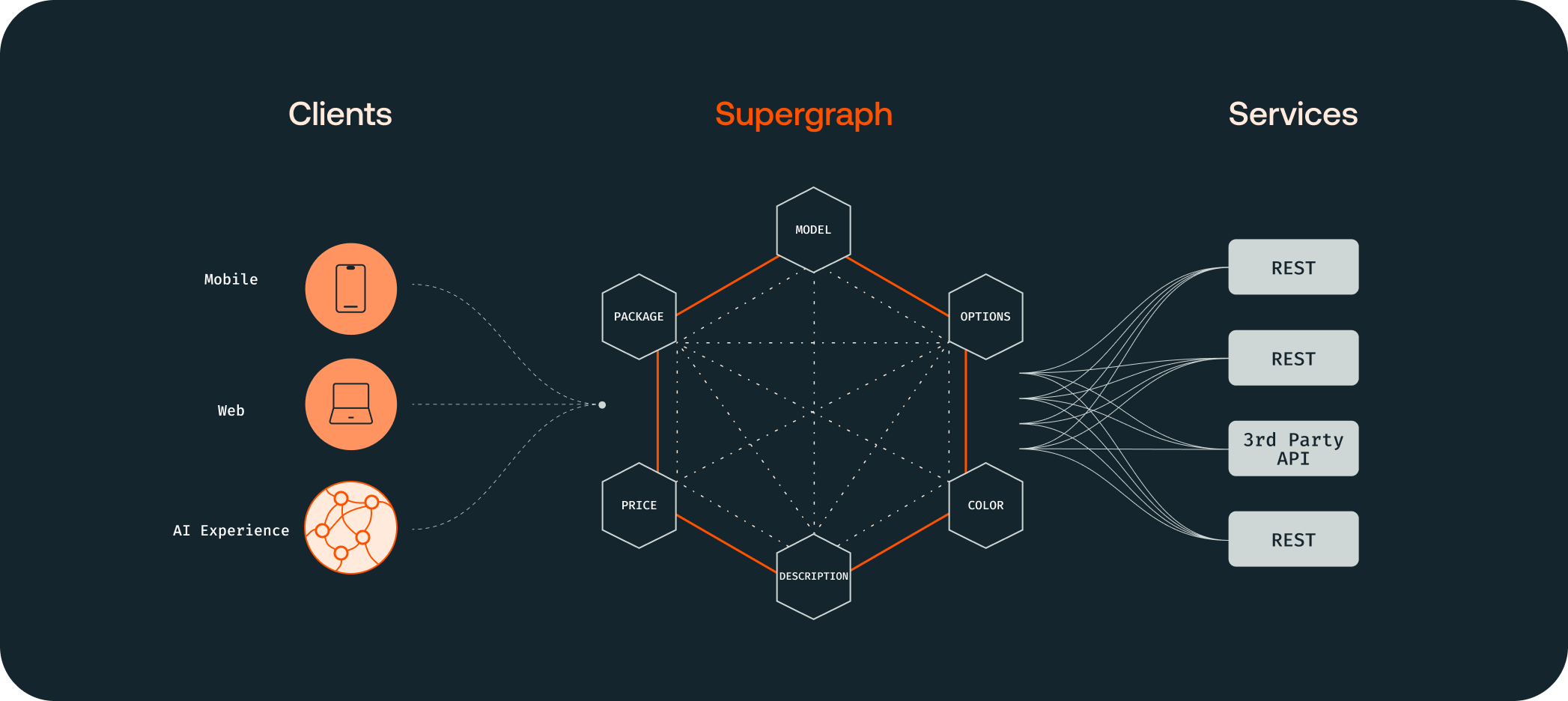
So why power these experiences with a supergraph?
Relational context: GraphQL enables backend teams to identify the key types and fields that the experience needs to do its job and the relationships between them. So if a promotion contains a product_name, an image, and a price, LLM-driven experiences can use a declarative query language to fetch this data with all of its useful context.
API aggregation: GraphQL is often seen as an alternative to REST, but they work well together. GraphQL provides a means to abstract an organization's plethora of REST APIs behind a single interface. It aggregates and orchestrates all of these API calls so that our LLM doesn’t have to.
Performance: Rather than forcing AI-integrated apps to make several roundtrips to fetch the data to serve a response, it can fetch the necessary data with a single request. This ensures answers are provided faster and allows for further performance optimization in the platform layer.
Iteration and evolution: GraphQL doesn’t require versioning, so it’s easier to test and roll out new data and context to our downstream experiences. We can iterate our responses faster with fewer concerns about breaking changes downstream.
Between all of these benefits, GraphQL federation is an ideal technology to build, test, and iterate any AI experience to be more engaging and helpful. It takes on the heavy lifting of working with APIs so that we can focus on our users and our product instead.
Learn how Netflix and Block are powering their AI-enabled experiences with APIs and GraphQL federation.
Most brands aren’t rolling out an open-ended LLM-integrated experience that attempts to answer almost anything under the sun. Take chatbots, for example. Chatbots are most effective when their scope is limited to a certain task or number of tasks. This makes them easier to fine-tune and also ensures we can provide better guardrails across our data. But users don’t always want to deal with 15 chatbots. They want one.
Using GraphQL federation, we can break up our chatbot into a set of different specialized capabilities without having to build and support a separate backend for each one. Best of all, we can give these chatbots new capabilities and help them do even more for our customers without redeploying the chatbot.
What could this look like?
Imagine we’re a car maker, and we’re building a chatbot that sits on the vehicle builder page of our website and helps customers pick options. It’s architecture might look something like this:
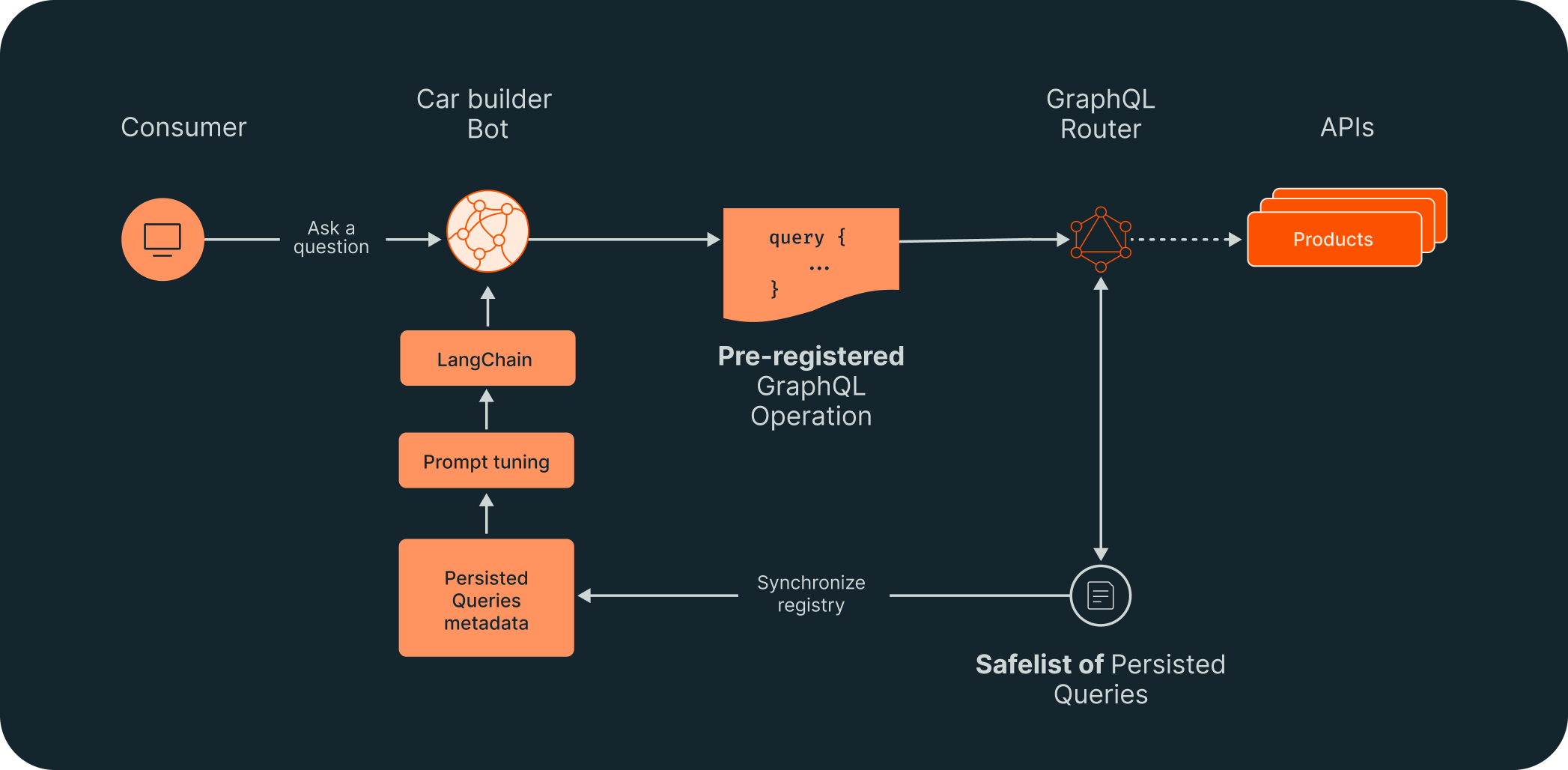
Our car builder chatbot requires a wealth of data in the backend. We need to define a model, color, package, options, account, account type, price, etc. GraphOS enables us to create a safelist of persisted queries, which is a way of predefining the data we can get back from an API request, without writing or maintaining a new service. A customer's question would then be answered using a set of these pre-registered operations defined by the development team.

But what if you want to roll out new capabilities, and iterate beyond just a car builder? Here is where GraphQL federation and GraphOS shine. When you want to ship new functionality, we can reuse this underlying data without writing a new bespoke experience API specific to the new capability we want to bring to our business. This means the same chatbot can help with things like car financing or customer service simply by updating the list of available queries.
Data access control is important in any experience we create, and AI-driven experiences are no different. As a centralized platform for clients to access data, a federated GraphQL layer is also ideal for centralizing the control of that data access down to the column level in a declarative and observable way.
Using the GraphOS platform and a feature called contracts, we can expose subsets of our data that are useful for our new and much more limited chatbot modules. We can build separate safelists with persisted queries to limit each module’s scope to only a set number of operations. Finally, as a centralized platform for clients to access data, a federated GraphQL layer is also ideal for centralizing the control of that data access down to the column level in a declarative and observable way.
To reduce risk, we are putting up intentional guardrails so that each customer experience can access the data they require and nothing more. By using GraphQL Federation underneath it all, we’ve also reduced the technical debt of backends-for-frontends that we must maintain and secure.
When you’re ready to launch the newly built chatbot to production, Apollo GraphOS provides metrics and insights to help, as well as workflows that enable you to safely build, test, and ship changes to your graph. A supergraph is the best way for clients to access data from a single endpoint, safelisted persisted queries allow us to pre-define the operations and shape of the data that a chatbot or other AI experience can expect, and with contracts, we can isolate the data available to these experiences from the rest of the data in our graph without creating a new backend for frontend (BFF) or API for the team to build, test, and maintain.