Overview
Before our server can resolve the data for a GraphQL operation, it first needs to extract and validate the operation itself. This involves a few steps that must take place before any datafetching occurs.
In this lesson, we will:
- Review how an operation is received, parsed, and validated by a GraphQL server
- Learn about the
PreparsedDocumentProviderinterface - Discuss the best practice of using query variables when caching operations
GraphQL operations and the server
Let's start by reviewing what exactly happens behind the scenes when our server receives a GraphQL operation.
The process begins when a client submits an operation in an HTTP POST or GET request. When our server receives the HTTP request, it first extracts the string with the GraphQL operation. It parses and transforms it into something it can better manipulate: a tree-structured document called an AST (Abstract Syntax Tree). With this AST, the server validates the operation against the types and fields in our schema.
If anything is off (e.g. a requested field is not defined in the schema or the operation is malformed), the server throws an error and sends it right back to the app.
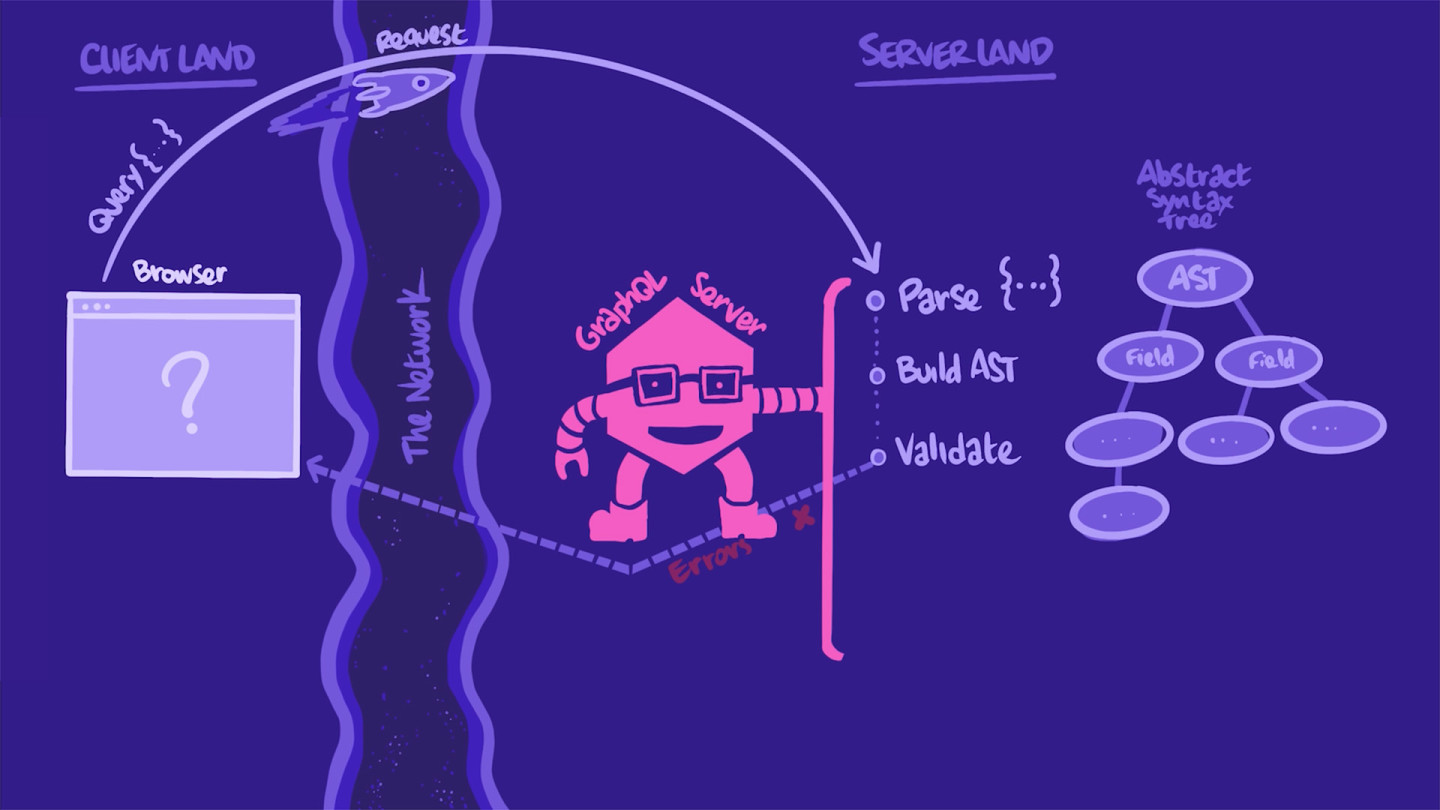
If the operation looks good, the server proceeds to "execute" it: for each field in the operation, the server invokes that field's datafetcher method. When all the fields have been resolved, the server packages up the data in a single JSON object that matches the shape of the original query. And back to the client it goes!
This process is efficient, but what happens when the server receives the same operation more than once? Well, it does what it has always done: it extracts the operation, parses it into an AST, and validates the result against the schema. Only after these steps are taken care of does the server proceed with invoking each field's datafetcher method. This means even if the server has already parsed and validated a particular operation once or twice before, it will continue to repeat these steps for each new request.
We can improve upon this process with operation caching.
Caching operation strings
When we equip our server to cache the operation strings it receives, we can avoid repeating two potentially expensive steps in the server's process: parsing and validating the request string. By creating a cache specifically for our GraphQL operations, the server can parse and validate a unique operation once, then refer to the cached document when it receives the same operation in the future.
To bring this functionality into our DGS server, we'll use the GraphQL Java library's PreparsedDocumentProvider interface. Before diving into our actual implementation, let's get an overview of how this interface works.
The PreparsedDocumentProvider interface
The PreparsedDocumentProvider interface works by storing GraphQL operations (referred to within the interface as Documents) in a cache instance that we provide (more on that in the next lesson!).
Whenever our server receives an incoming operation string, the PreparsedDocumentProvider implementation uses its getDocumentAsync method to check whether the same operation already exists in the cache.
public interface PreparsedDocumentProvider {CompletableFuture<PreparsedDocumentEntry> getDocumentAsync(ExecutionInput executionInput,Function<ExecutionInput, PreparsedDocumentEntry> parseAndValidateFunction);}
The getDocumentAsync method takes two parameters: the first is the current "execution input", an object that contains all sorts of data about the query being executed, including the operation string.
The second is a function, parseAndValidateFunction, which is called if the provided operation string is not present in the cache. This function takes care of the necessary parsing and validation steps before sending the operation on its way to the datafetcher methods. But in the process, the operation itself gets cached for next time!
The CachingPreparsedDocumentProvider class
Let's take care of creating the class that will implement our PreparsedDocumentProvider interface.
In the com.example.listings package, right alongside the ListingsApplication file, create a new file called CachingPreparsedDocumentProvider.java.
📦 com.example.listings┣ 📂 datafetchers┣ 📂 dataloaders┣ 📂 datasources┣ 📂 models┣ 📄 CachingPreparsedDocumentProvider┣ 📄 ListingsApplication┗ 📄 WebConfiguration
To start, we can import the Spring framework's Component annotation, along with PreparsedDocumentProvider and PreparsedDocumentEntry from the graphql package. (We'll use PreparsedDocumentEntry shortly!)
import org.springframework.stereotype.Component;import graphql.execution.preparsed.PreparsedDocumentProvider;import graphql.execution.preparsed.PreparsedDocumentEntry;
Next, we'll update our class definition to implement the PreparsedDocumentProvider interface. And let's not forget to apply the @Component annotation so that this file is detected as a bean in our application (a class instance managed by the Spring container).
Here's how your class should look.
package com.example.listings;import org.springframework.stereotype.Component;import graphql.execution.preparsed.PreparsedDocumentProvider;import graphql.execution.preparsed.PreparsedDocumentEntry;@Componentpublic class CachingPreparsedDocumentProvider implements PreparsedDocumentProvider {// TODO}
Great! That's our boilerplate taken care of. You might be seeing some red squigglies right now, but not to worry: we'll build out the remainder of our class in the next lesson.
Caching tip: Use query variables
We consider the use of query variables a best practice in GraphQL in general, but this convention becomes extra important when using the PreparsedDocumentProvider to cache GraphQL operations.
Take a look at the following query.
query GetListingAndAmenities {listing(id: "listing-1") {titledescriptionnumOfBedsamenities {namecategory}overallRatingreviews {idtext}}}
There's nothing wrong with this query syntax—but stored in our cache, this operation is valid for one listing only: the listing with ID listing-1!
If we ran the same operation again, swapping in a different listing ID, we wouldn't see any benefits from caching the first operation. By defining its listing ID in-line, our cached operation is too specific: it'll save us time on the parsing and validation steps only when we query for the exact same listing again.
query GetListingAndAmenities {listing(id: "listing-2") {titledescriptionnumOfBedsamenities {namecategory}overallRatingreviews {idtext}}}
With query variables, we can abstract away the specifics and focus instead on the generic operation: the fields it includes and the names of the variables involved.
query GetListingAndAmenities($listingId: ID!) {listing(id: $listingId) {titledescriptionnumOfBedsamenities {namecategory}overallRatingreviews {idtext}}}
Now if our client were to send this operation twice, one for listing-1 and another for listing-2, we'll see the benefits of operation caching: the second time the server receives a request, the parsing and validation steps will be skipped.
Note: What about the actual variable values passed at runtime? They can be found on the execution input object that gets passed into the interface's getDocumentAsync method. We'll explore this object in the next lesson.
Practice
Key takeaways
- We can implement the
PreparsedDocumentProviderinterface to do the following:- Retrieve operations that have already been parsed and validated from a cache
- Parse and validate operations that are not yet in the cache, caching them in the process
- By using query variables (rather than in-line values), we can store generic operations in the cache that can be retrieved and used for multiple different values. (For instance, one operation can serve up data for any listing ID we provide it!)
Up next
In the next lesson, we'll finish our class implementation by adding our methods and a high-performance cache implementation.
Share your questions and comments about this lesson
This course is currently in
You'll need a GitHub account to post below. Don't have one? Post in our Odyssey forum instead.