Now we know more about the journey a GraphQL query takes from client to server and back. Let's use this newfound knowledge for our Catstronauts app.
First, let's ask ourselves a few questions:
- Where is our data stored, and how is it structured?
- Is that structure different from our client app's needs and schema?
- How can our resolver functions access that data?
The data that resolvers retrieve can come from all kinds of places: a database, a third-party API, webhooks, and so on. These are called data sources. The beauty of GraphQL is that you can mix any number of data sources to create an API that serves the needs of your client app.
Where is our data stored?
We'll be using a REST API located at https://odyssey-lift-off-rest-api.herokuapp.com/.
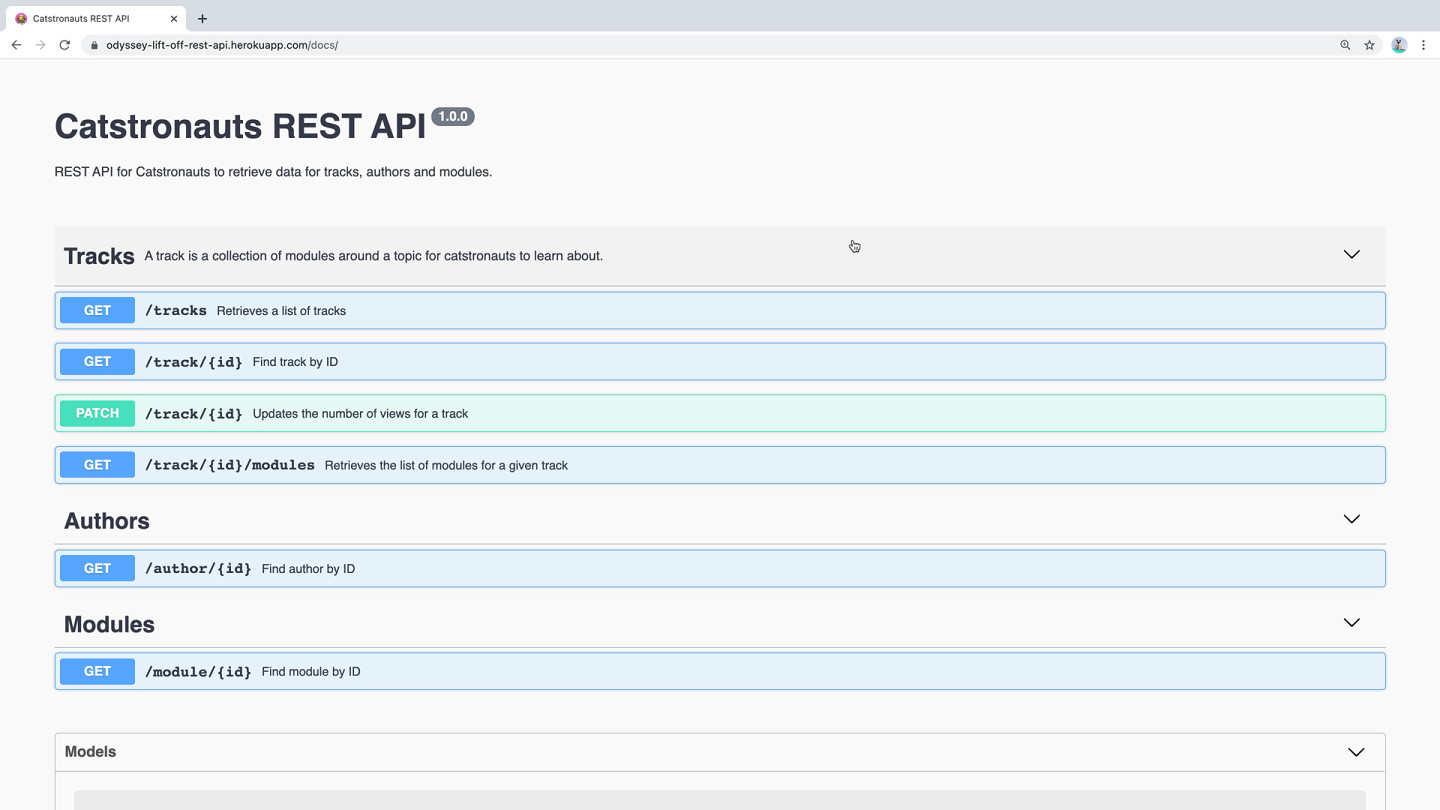
Looking at the API documentation, it looks like there are 6 endpoints available:
GET /tracksGET /track/:idPATCH /track/:idGET /track/:id/modulesGET /author/:idGET /module/:id
How is our data structured?
The next question we need to figure out is how our data is structured in our REST API. This impacts how we'll need to retrieve and transform that data to match the fields in our schema.
For our current feature of displaying tracks on the homepage, let's start with the /tracks endpoint. To test this endpoint from the REST API documentation, we can click Try it out and then Execute.
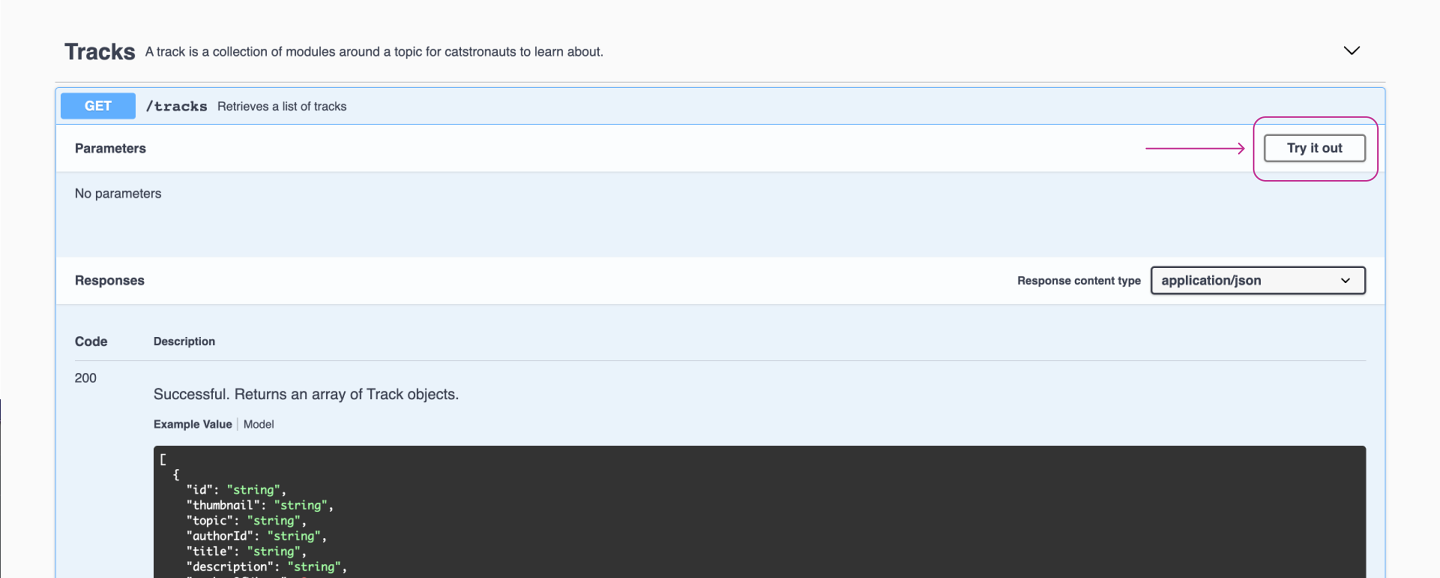
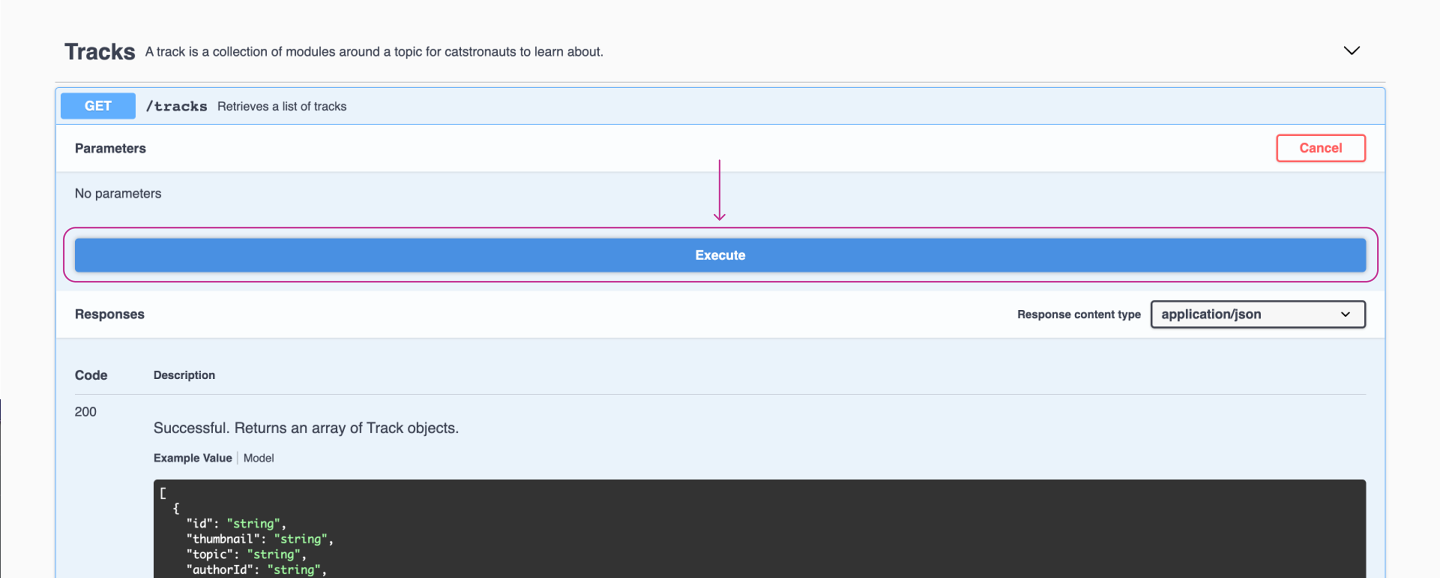
We get a JSON response back:
[{"id": "c_0","thumbnail": "https://res.cloudinary.com/apollographql/image/upload/v1730818804/odyssey/lift-off-api/nebula_cat_djkt9r_nzifdj.jpg","topic": "Cat-stronomy","authorId": "cat-1","title": "Cat-stronomy, an introduction","description": "Curious to learn what Cat-stronomy is all about? Explore the planetary and celestial alignments and how they have affected our space missions.","numberOfViews": 0,"createdAt": "2018-09-10T07:13:53.020Z","length": 2377,"modulesCount": 10,"modules": ["l_0", "l_1", "l_2", "l_3", "l_4", "l_5", "l_6", "l_7", "l_8", "l_9"]},{...},]
The response includes an array of tracks, which is a good start. Let's see in more detail what matches, referring back to the Track type in our GraphQL schema:
type Track {id: ID!title: String!author: Author!thumbnail: Stringlength: IntmodulesCount: Int}
The array includes properties that we need in our homepage Track Card:
idthumbnailtitlemodulesCountlength
The array also includes a bunch of stuff we don't need for now:
topicdescriptionnumberOfViewscreatedAtmodules
It's okay that the array includes fields that we don't need. Our resolver functions will take care of filtering the data properties to match only what the query asks for.
Notably, the array doesn't include the author information we need, such as name and photo. However, it does include an authorId. We can provide this to the /author/:id endpoint, which takes an ID parameter and returns the details of that author.
{"id": "cat-1","name": "Henri, le Chat Noir","photo": "https://images.unsplash.com/photo-1442291928580-fb5d0856a8f1?ixlib=rb-1.2.1&q=80&fm=jpg&crop=entropy&cs=tinysrgb&w=1080&fit=max&ixid=eyJhcHBfaWQiOjExNzA0OH0"}
Looking at the Author type in our schema, we get everything we need:
type Author {id: ID!name: String!photo: String}
We'll need to call this /author/:id endpoint for each track in the array that we received in the previous call. Then we'll need to stitch the results together so that we end up with the shape of the data that our resolver, and our query, is expecting.
We know our data is provided by a REST API and how that API's data is structured. Next, we'll find out how our resolver functions can access that API.
Share your questions and comments about this lesson
Your feedback helps us improve! If you're stuck or confused, let us know and we'll help you out. All comments are public and must follow the Apollo Code of Conduct. Note that comments that have been resolved or addressed may be removed.
You'll need a GitHub account to post below. Don't have one? Post in our Odyssey forum instead.