We know where our data is, and we understand how it's structured. Awesome. Now to access it from our resolvers!
Our GraphQL server needs to access that REST API. It could call the API directly using fetch, or we can use a handy helper class called a DataSource. This class takes care of a few challenges and limitations that come with the direct approach.

To better understand those challenges and limitations, let's start with fetch before we create a DataSource.
When making calls to a REST API in a Node.js environment, we might use a library like axios or node-fetch. These provide easy access to HTTP methods and nice async behavior.
Using node-fetch, retrieving all tracks from our /tracks endpoint looks like this:
fetch("apiUrl/tracks").then(function (response) {// do something with our tracks JSON});
This gives us our array of tracks, but we're still missing author information. For each track in the array, we need to call the /author/:id endpoint like so:
fetch(`apiUrl/author/${authorId}`).then(function (response) {// this is the author of our track});
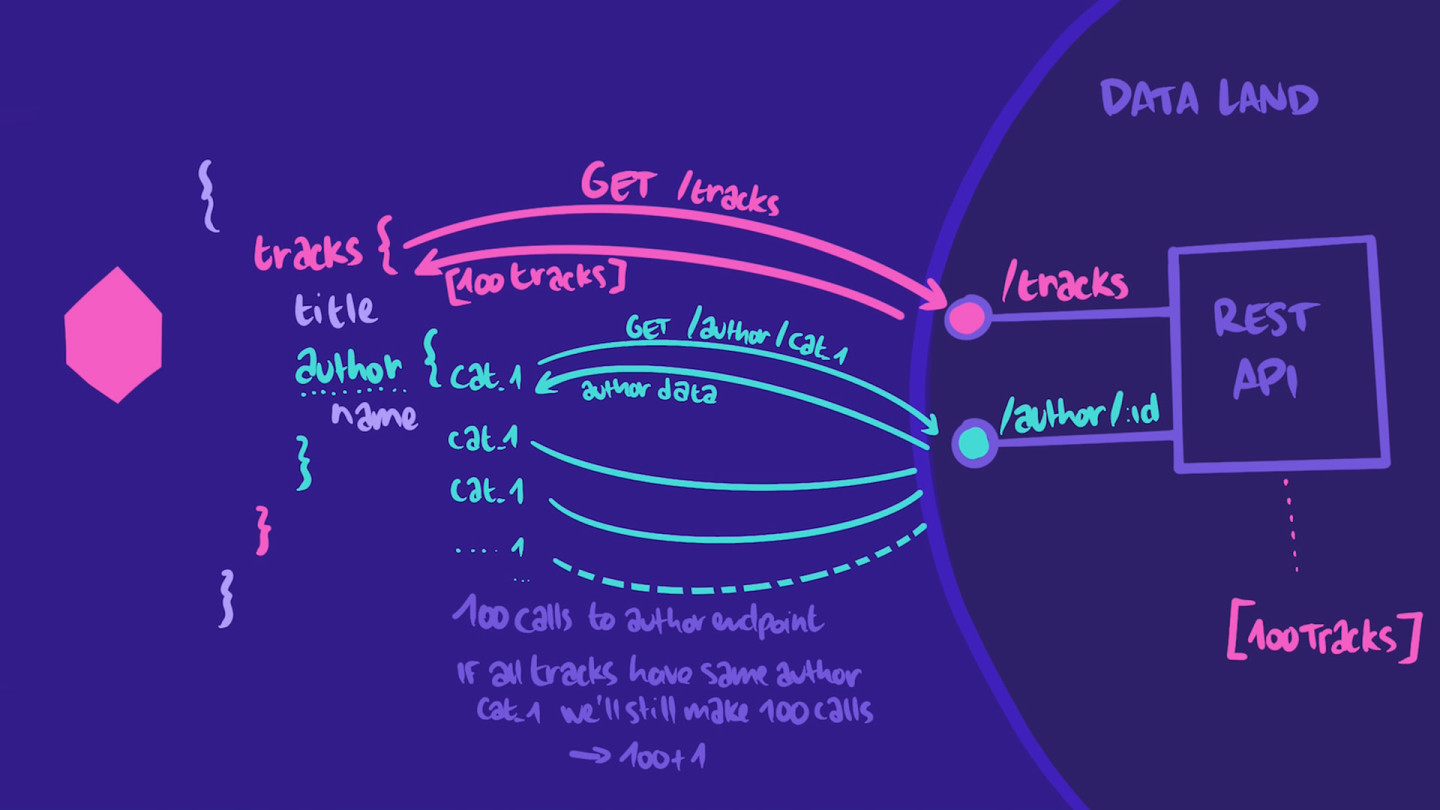
Let's say our /tracks endpoint returns 100 tracks. Then we'd make one call to get the array, followed by 100 additional calls to get each track's author info.
Now, what if our 100 tracks were all made by the same author? We'd make one call for the tracks, retrieve our 100 tracks, then make 100 calls to get the exact same author.
Sounds pretty inefficient, right? We'd end up making 101 calls where we could have made only two.
This is a classic example of the N+1 problem. "1" refers to the call to fetch the top-level tracks field and "N" is the number of subsequent calls to fetch the author subfield for each track.
{tracks {# 1titleauthor {# N calls for N tracksname}}}
Additionally, in the context of our app and this specific query, we're not expecting the homepage to change very frequently. Maybe a new track is added every few weeks. It would be nice to make use of a cache to avoid unnecessary calls to our REST API. Conveniently, our REST API already sets cache headers for its endpoints.
With GraphQL, one query is often composed of a mix of different fields and types, coming from different endpoints, with different cache policies. So how should we deal with caching in this context?
We're starting to really feel the limits of our simple fetch approach.
To solve these problems, we need something specifically designed for GraphQL, that will efficiently handle resource caching and deduplication for our REST API calls.
And because it's a very common task to fetch data from REST when building a GraphQL API, Apollo provides a dedicated DataSource class for just that: the RESTDataSource.
By implementing a RESTDataSource on your server, all of the challenges we just saw are taken care of out of the box.
Let's look at how to extend and implement this RESTDataSource in our Catstronauts app.
Share your questions and comments about this lesson
Your feedback helps us improve! If you're stuck or confused, let us know and we'll help you out. All comments are public and must follow the Apollo Code of Conduct. Note that comments that have been resolved or addressed may be removed.
You'll need a GitHub account to post below. Don't have one? Post in our Odyssey forum instead.